Dependencies
Baler needs the following packages to compile
- Qt4, qt-mysql
- libQtGui
- libQtCore
- libQtSql
- boost (not just headers, but also compiled libraries. More recent yum installs of boost will have these libraries.)
- libboost_program_options
- libboost_iostreams
- Note that libboost_iostreams may need install of bzip2-devel
- Perl
- perl-Algorithm-Diff (yum install will also make use it is in the right place wrt @INC. you can also get it via CPAN)
And, it needs MySQL as its data storage (for visualization & counting)
MySQL Settings
MySQL is used for data storage. Data processed by logcluster2.pl (see below) is entered into a database. This process is fairly rapid, even for large datasets provided that you set the following in your /etc/my.cnf (mysql config file):
innodb_flush_log_at_trx_commit=2
Building
Edit the Makefile and/or Associated Files
In common.mk (which is included in the Makefile)
- Set the preferred build directory (BUILD_DIR)
- If you want to see what is happening during the build, feel free to unset QUIET_BUILD (or set it to be empty)
- Set QT_INCLUDE_DIR, QT_LIB_DIR
- set BOOST_INCLUDE_DIR, BOOST_LIB_DIR
Calling Make Command
For example:
make -j8 #(to make all: scripts, log-clustering2 and baler-gui) make -j8 all #(same as above) make -j8 log-clustering2 #(make only log-clustering2) make -j8 baler-gui #(make only baler-gui) make -j8 scripts #(make the scripts)
Expected Outputs
After the make finished, all of the executable binaries (and scripts) will be put in $(BUILD_DIR)/bin those files are:
- baler-gui
- log-clustering2
- meta-cluster-for-baler.pl
- gen-meta-patern.pl
- log-processing.pl
These files are needed to be present in $PATH for running the clustering and gui. So, PLEASE DON’T FORGET TO ADD $(BUILD_DIR)/BIN INTO $PATH VARIABLE
And we’re done building!
Running
There are two parts of baler, the back-end (log-clustering2) which determines the patterns and does the meta-clustering and the front-end (baler-gui) which displays the patterns. Here are how to run them.
The Back-End Log-Clustering2
- add $(BUILD_DIR)/bin into your PATH variable
- Database configuration
You have to make sure first that the needed tables and procedure are in some schema. The needed tables can be initialized with $(BALER_SOURCE)/log-clustering/sql/baler.sql (this will not drop database, but will drop tables if exist). If ‘ovisBaler’ is your schema (i.e., name of your database), please run the following after creating the database called ovisBaler. Note that you can run baler.sql on an existing ovis database and it will add the additional baler tables into that database or you can run baler.sql on an empty database. You will probably be doing the latter.
mysql ovisBaler < $(BALER_SOURCE)/log-clustering/sql/baler.sql
- log-clustering2 configuration
Please specify the following in a configuration file (any-name.cfg):
eng-list=/path/to/english-wordlist (one word per line; e.g. mylist-w-variation) svc-list=/path/to/service-list (one service name per line; e.g. all.services) host-list=/path/to/host-list (one hostname per line) log-format=syslog|cray project-dir=project-output-directory (this directory stores pattern, message and token mapping info; e.g. old glory.data directory) db-server=localhost db-username=ovis db-password=somepassword db-schema=ovisBaler db-type=mysql year=2005 (syslog do not provide year information, so we have to give it) meta-ratio=0.3
The db-XXXX can be set to other values and log-clustering2 will understand and put the data according to db-XXXX settings. db-schema is the name of your database. An eng-list and svc-list are provided. You will have to make your host list. This file should have one host per line where the hostnames are those that are in the format of your logfile. This information is used to determine which log lines are reported by which hosts and will be used in processing the headers and in the gui display. log-format with either be syslog or cray. This is necessary to determine how to process some line header information. Once the log-clustering2 is finished, patterns, meta-clusters, and visualization information for the gui will have been created in your project-dir. NOTE: the current code REQUIRES that the database have a password.
- Run log-clustering2 as follows:
log-clustering2 --config=<your-config-file> <log file1> <log file 2> ...
for example:
log-clustering2 --config=syslog.cfg glory-syslog-ng-recleanse/*/*
(the glory-syslog-ng-recleanse/*/* will be expanded, by bash, to a list of glory-syslog-ng-recleanse/glory1/2009.02.28.cleansed … ) Once the log-clustering2 is finished, patterns, meta-clusters, and visualization information for the gui will have been created in your project-dir.
Multiple sequential runs of baler on new additional data: You can run log-clustering2 on a new dataset and it will merge things into a previously processed dataset. It will add in the new patterns, recognizing matches to existing patterns and handle those appropriately, and the info (matches to already existing patterns and addition of new patterns) is stored in the output files and db. Then when the meta clustering runs, the whole meta clustering is redone on all the pattern data (not the raw files) and the meta clusters are recalculated for everything. Thus, this last is non-deterministic, but it will include all the pattern contributions.
The Front-End Baler-GUI
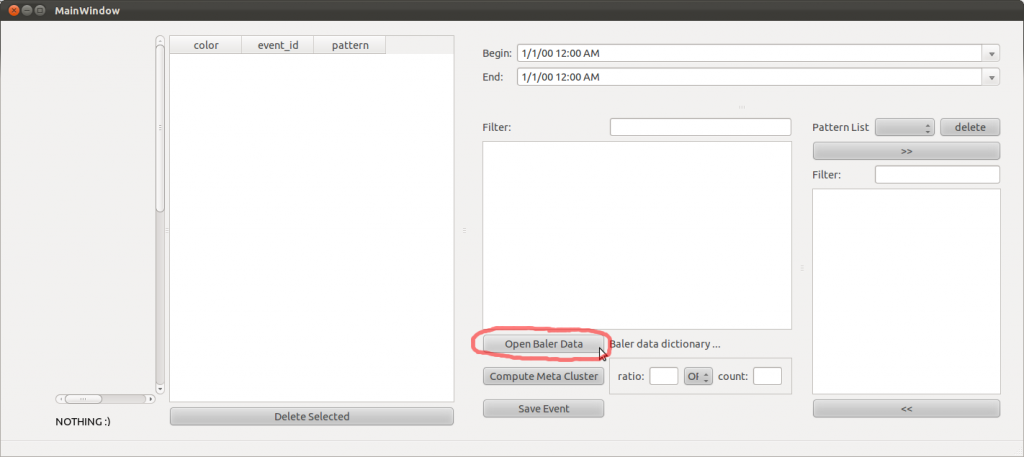
- Call baler-gui from a command line to bring up the display.
- Load data: Click “Open Baler Data” (as shown in the picture below) and specify the path to your data directory
- Using the Display
Baler uses the English and service dictionaries to discovery patterns in the data. Words in the dictionary are retained, all other items, such as node ids, process ids, numbers in IP addresses or memory banks can become wild cards. Baler then clusters these patterns based on level of similarity to produce meta-clusters of patterns. For example, patterns are discovered such as “tests have failed in normal mode” and “tests have failed in suspect mode”. These patterns are then grouped into the meta-cluster “tests have failed in * mode”.

Meta clusters may be formed even from messages of differing number of words.
Log files of many hundreds of thousands of lines are then reduced into a small number of meta-clusters representations that are easy to examine. Details of which node, which memory bank etc are hidden at the top level, making it easy to examine what types of things are occurring and how frequently.
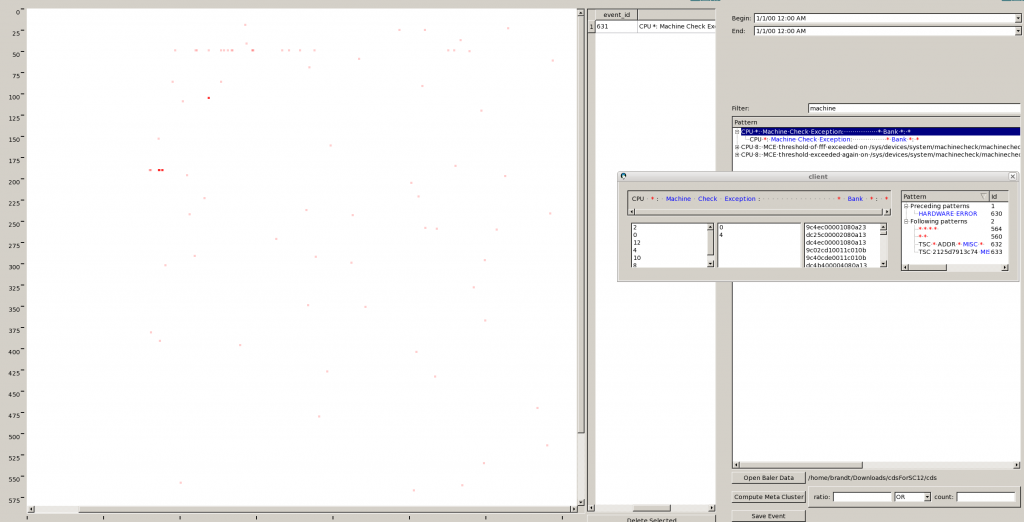
3.1 Examining Patterns: Patterns are examined in the Pattern Window. The filter allows you to display only patterns that contain certain words. Double clicking on a pattern brings up a window by which wild cards can be examined (double click on wild card. Preceeding and Following patterns and their number of occurrences are shown to aid in the processing of multiline patterns.
Tuning the meta-ratio – The meta-ratio sets a similarity ratio used for grouping patterns. Emperical evidence leads us to usually start this at 0.3. However, if you find that that your patterns are over or undergrouped then lower or raise this value and run the logcluster2.pl again. Under or overclustering usually occurs in cases where 1) your logs may be dominated by messages of a certain type that contain many similar words, such as Lustre messages that may have a lot of the same english words compared to the actual wild cards 2) there are a lot of line breaks in your messages. This latter can occur when you have many hosts reporting to a single log server and the messages get intertwined. In this case you may have a lot of patterns that should be identical but are not becuase of unfortunate line breaks.
3.2 Viewing Events – You can drag and drop patterns from the Pattern window onto the Event Window. Colored dots in show the occurrences of that pattern in time. X axis is time. Y axis is host id. These host ids are numbers which are the order in which the hosts were specified in your host-list (this will be changed to have better naming in the display in future). Multiple patterns may be dropped on the display. If you hover over an event in the disply more information about that event (host, pattern details, time) will be displayed.
You can scroll and zoom in X and Y.
- Left click: zoom in (time axis (X))
- Right click: zoom out (time axis (X))
- Ctrl + Left click: zoom in (node axis(Y))
- Ctrl + Right click: zoom out (node axis(Y))
- Tool tips over a pixel show event details (node, time and messages)
Notes
- log-clustering2 will store database connection information for you in the result directory in a file called <proj.out.dir>/dbconn. This is used by the gui to connect to the database. It is stored in plain text.
Each line in the file represent database information as follows:
1: db_hostname 2: db_type 3: db_schema 4: db_user 5: db_passwd
For example:
1: localhost 2: QMYSQL 3: ovisBaler 4: ovis 5: somepasswd
would give baler all information except the password (for non-password-needed connection) PLEASE NOTE THAT THE NUMBER: IS JUST A LINE NUMBER. DON’T PUT 1: OR 2: IN THE REAL FILE.
- The GUI requires you to select a data dir. This is the project-dir with the files that were created by the log-clustering2.pl command. This browser only works for the local machine (as opposed to the database which can be on a remote machine). In practice, then, you will probably have your data dir and your database both local.
- Running meta-clustering from the GUI (not recommended):
- You can run the meta clustering from the GUI, but currently the GUI will freeze and the Compute Meta Cluster button will remain grey while this is going on.
- If you run the meta clustering from the GUI make sure that meta-clustering-for-baler.pl is in your path from where you ran the gui.
Long Term Data Maintenance
- You can easily write a script to run log-clustering2.pl as a cron job (one will be forthcoming). As noted above, running log-clustering2.pl to add new data into an existing database does the right thing.
- You can easily delete all data by dropping the entire database (a script to do so will be forthcoming). It is not recommended to try to drop out partial data.
Performance Issue with MySQL
Baler stores all logged events in a single MySQL table (called log_record), and working with large dataset (e.g. >20 millions) results in a large MySQL table so that the table index cannot fit in the main memory. Hence both insert operation and query operation will be significantly slower and thus respectively affect log-clustering2 and baler-gui.
This issue will be addressed in the next version of Baler.