High Performance Computing Monitoring, Analysis, and Visualization
OVIS is a modular system for HPC data collection, transport, storage, analysis, visualization, and response. The OVIS project seeks to enable more effective use of High Performance Computational Clusters via greater understanding of applications’ use of resources, including the effects of competition for shared resources; discovery of abnormal system conditions; and intelligent response to conditions of interest.
OVIS components are modular and can be deployed and used independently.
Data Collection, Transport, and Storage
The Lightweight Distributed Metric Service (LDMS) is the OVIS data collection and transport system. LDMS provides capabilities for lightweight run-time collection of high-fidelity data. Data can be accessed on-node or transported off node. LDMS can store data in a variety of storage options.
We develop and use the Scalable Object Store (SOS) as one of our storage options supporting high ingest rates and python-based analytics development. LDMS won a R&D 100 award in 2015.
Analysis and Visualization
OVIS data can be used for understanding system state and resource utilization. The current release version of OVIS enables in transit calculations of functions of metrics at an aggregator before storing or forwarding data to additional consumers. Complex computations and long-time range computations are encouraged to be performed on a data storage option.
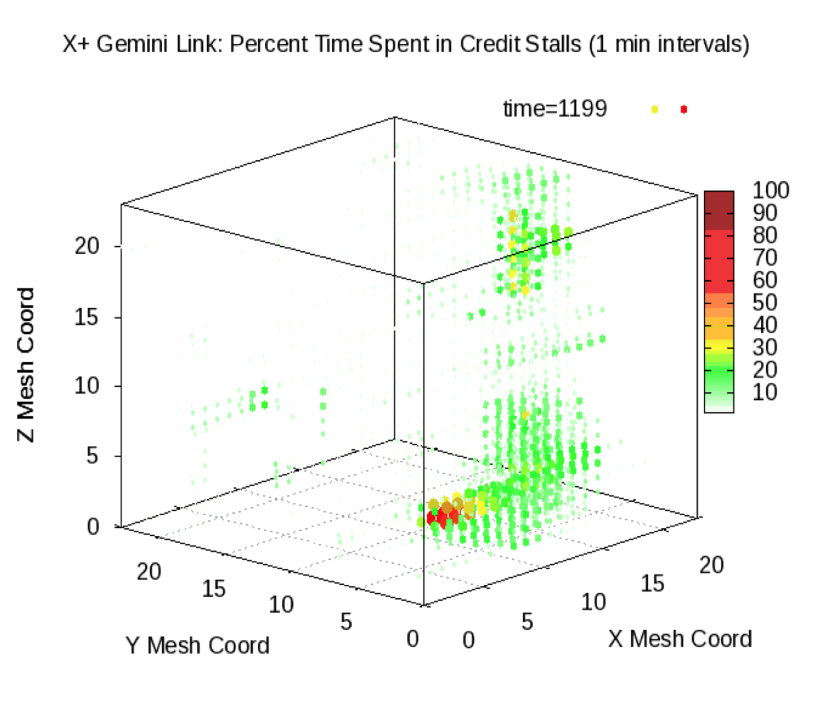
OVIS has been used for investigation of network congestion evolution in large-scale systems.
Additional features in development include association of application phases and performance in conjunction with system state data.
Log Message Analysis
OVIS analyses include the Baler tool for log message clustering.
Decision Support
The OVIS project includes research work in determining intelligent response to conditions of interest. This includes dynamic application (re-)mapping based upon application needs and resource state and invocation of resiliency responses upon discovery of potential pre-failure and/or abnormal conditions.
OVIS Support
Information on using OVIS capabilities can be found at OVIS release wiki. This includes tutorial materials, an active issues list for discussions and the LDMS User’s Group Conference (LDMSCON).